Dataset Creation
Please see the section ‘Loading Data’ for a detailed guide on how to bring data into the TrueState platform.Data Schema
The datatypes of each column will be automatically determined during the ingestion step. They consist of one of four built-in types:| Type | Description |
|---|---|
| STRING | Text values of arbitrary length (e.g. names, descriptions, categorical codes). |
| NUMBER | Numeric values, including integers and floats (e.g. counts, prices, measurements). |
| BOOLEAN | True/false flags or binary indicators (e.g. “active/inactive”, “yes/no”). |
| DATETIME | Timestamps or dates (e.g. event times, birthdates, log timestamps). |
AI Description
The Dataset will be processed by an AI to create an enriched description that considers the datatypes, column names, and distribution of values. This description is provided to any AI operations as context, in order to prevent hallucinations. This description can be viewed on the Dataset details page.Data Dictionary
The Data Dictionary is an optional setting allowing you to annotate the columns directly, in order to provide further context about the content of each column. This additional context is very helpful when asking the bot to perform operations on the data. The Data Dictionary can also be auto-generated by an AI by clicking the ‘Auto-generate’ button on this page.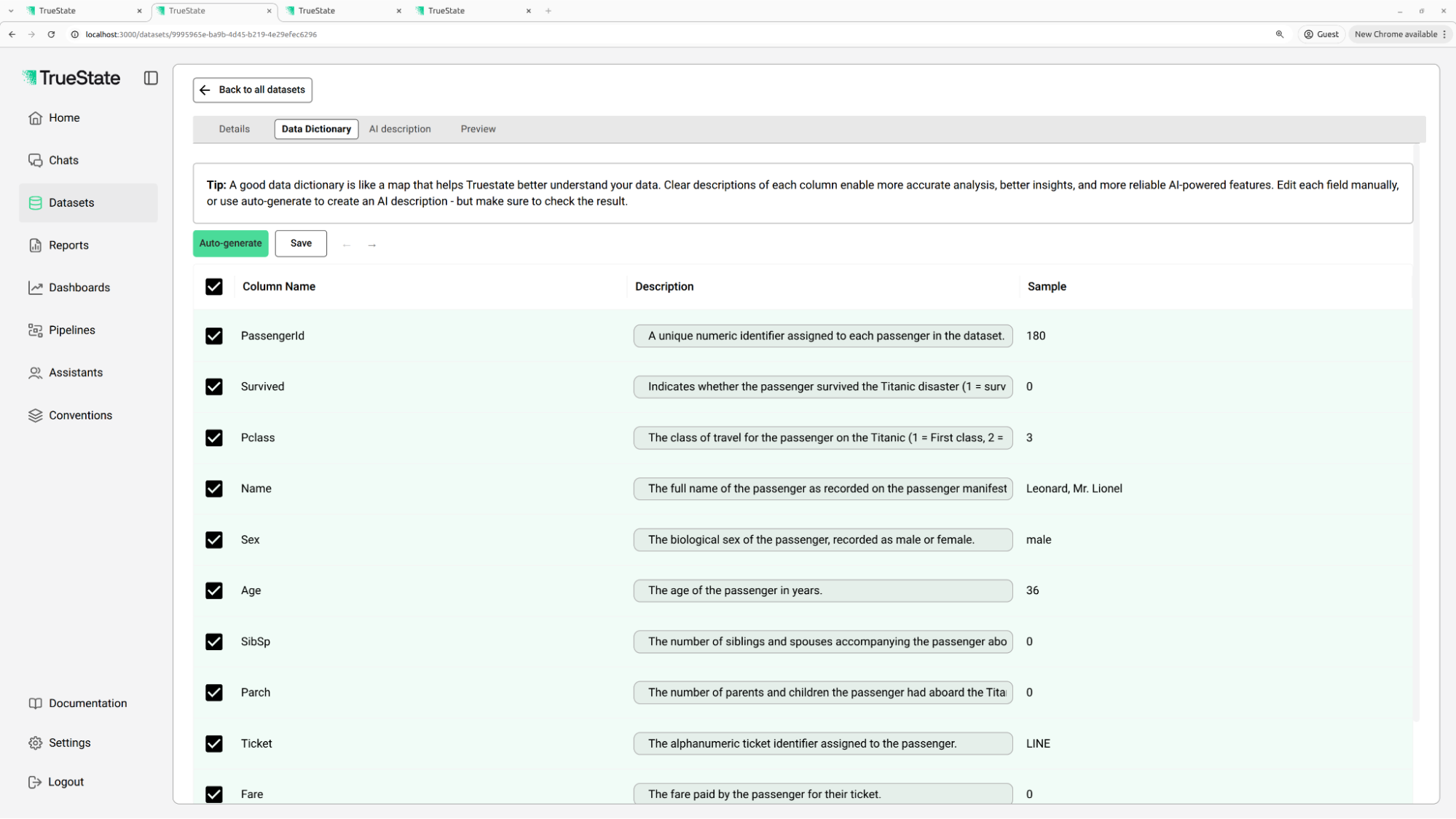
Dataset Upsert API
Advanced users may wish to upsert their datasets. The upsert API has been documented below.- url: https://platform-api.truestate.io/datasets/upsert/
- method: PUT
- the request header must include “api-key: truestate-api-key-string”
dataset_name: the name of the dataset to be upserted. If the dataset doesn’t already exist, it will be created as part of the API.row_unique_identifier: the column name that is unique to the row (e.g. id), this is required for the update operation.data: an array of json objects, with each object representing a rowdata_schema: Optional. Specify the schema in the ‘data’ field. It contains key value pairs of column_name -> column_type. column_name is the top level field in the JSON objects, DO NOT provide the inner nested fields. If not specified, the schema will be automatically inferred.
- INTEGER
- FLOAT
- STRING
- BOOLEAN
- JSON
- When it is a new dataset that doesn’t exist yet, the first object in
dataarray CANNOT containnullvalue in any field. Because the to be created dataset’s schema will not be inferred with null value. - The platform only allows 20 concurrent events to process for a single dataset
- Maximum size for the
datafield is ~1G